In our last post, we provided an introduction to graph thinking and the concept of nodes (or vertices) and edges (or links) as a way to describe networks. As examples, we pointed to Facebook (a social graph with connections between people and the things that people like) and Google (which uses the connections between web pages as a measure of relevance).
You might be asking yourself, “How does this apply to engineering documents?” and more importantly, “How will this help me save time at work, increase productivity, and reduce errors?” We will answer these questions in this post.
Documents as Graphs
Consider any engineering document: an industry standard, an internal corporate specification, a customer-provided specification, a work instruction, a test plan, etc. Each document comprises a series of concepts that, ideally, follow a logical sequence.
These documents are also often chock-full of text, tables, graphs, equations, drawings, and images — what we call “data elements”. Each of these elements represents a concept that is related to other concepts within the document. Each concept can be thought of as a node in a small graph. The way the concepts are organized and the way they reference and relate to each other, are the links. In short, the information within any technical document can be represented in form of a graph.
Engineering Documents Are Also Connected to Other Documents
The data elements within engineering documents also refer to concepts and data elements in other documents. Consider even a simple technical data package (TDP). The TDP contains drawings with notes that refer to other documents in the package. These documents, in turn, may have references, notes, and links to additional documents. (The additional documents referred to could be industry standards or regulations.) The end result is a nasty thicket of interrelated documents and requirements.
Consider the Technical Data Package for the Army Combat Uniform (ACU)
The technical data required to produce the Army Combat Uniform consists of nearly 200 references to 98 documents, a total of 5,053 pages from 13 document sources. Today, these documents are typically standalone PDF or MS Word files on a shared drive. The fact that these documents — and the data elements contained within them — are in individual “dead text” format, disconnected from each other, makes it very difficult for users to find the information they need and to understand the full context of what they are reading.
While this set of documents doesn’t look like a graph today, it can be thought of as a collection of nodes/concepts yearning to be linked to each other! Here’s what a simple network (or graph) of references and conceptual connections for this TDP looks like:
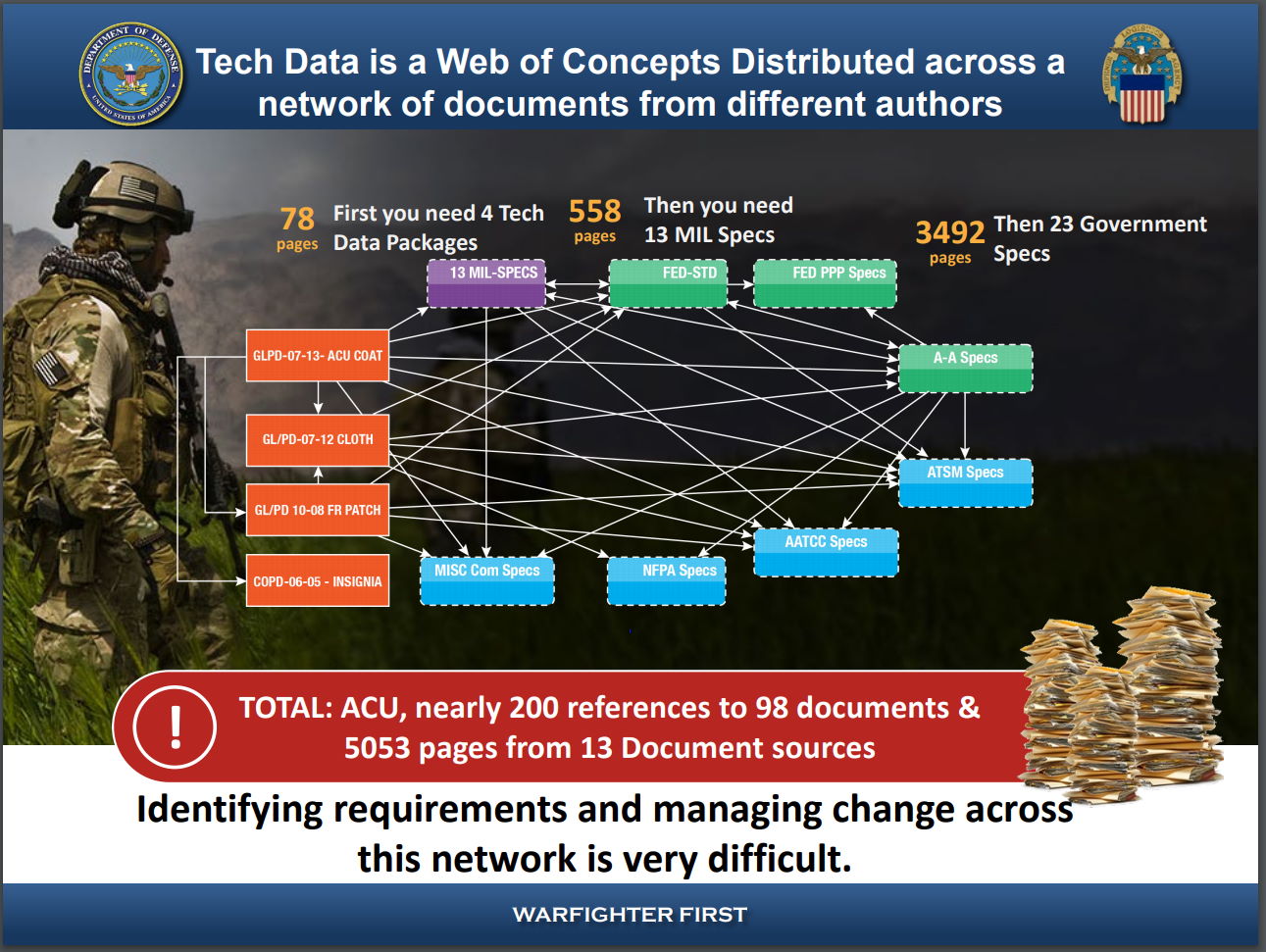
Luckily, all of these shortcomings can be eliminated when the documents are digitized and the data elements and concepts are truly linked in a graph. That’s where SWISS comes in.
SWISS Weaves Concepts Together into an Engineering Knowledge Graph
In theory, you could create all the links and relationships in a technical data package yourself by reading all the documents, understanding every concept, converting the documents to HTML, and manually creating links to the right sections of every document. Some users might undertake this manual effort using enterprise requirements management tools. Either way, it’s unnecessary and time-consuming manual labor, and you would make a bunch of mistakes! Moreover, when a document changed, you would have to manually update all the links yourself — assuming you were able to catch all the changes!
Fortunately, SWISS can do most of this work dynamically without human intervention. SWISS uses semantic analysis and artificial intelligence (AI) to “liberate and contextualize” each data element by automatically linking related concepts in a document to related concepts in other documents. Every concept with a document becomes a node in the graph database and each relationship or reference is a connection (or vertice) in the graph. Every piece of data understands its relationship to every other piece of data and even understands the status of that connection or link.
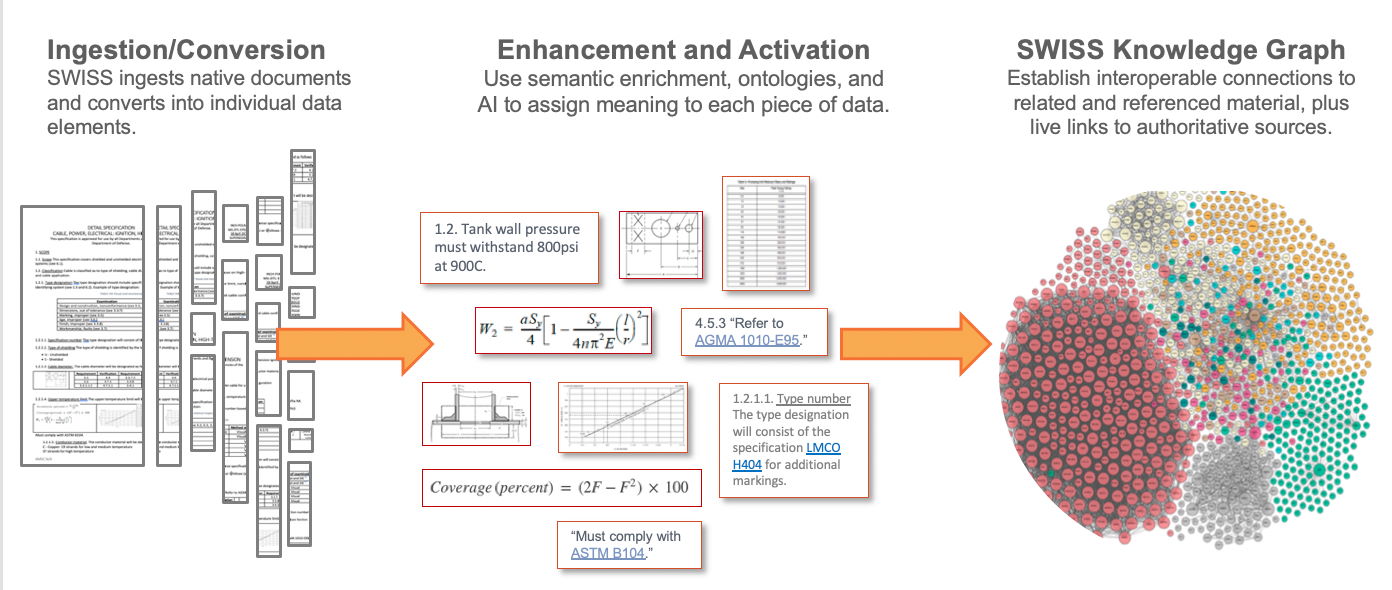
Benefits of Documents as Digital Models and the SWISS Knowledge Graph
Once the concepts and relationships within documents are mapped in a graph database (i.e. once the documents are converted to digital models), there are significant benefits to engineering organizations and individual users:
- A clickable table of contents is automatically created with no manual effort.
- Standalone documents become completely interoperable with links between concepts and references. Imagine clicking from your internal company spec to an AWS standard, to an internal quality test plan. This entire click-path can be created automatically based on connections between data.
- In addition to clicking from document to document, you can click from concept to concept. For example, when a reference says “Use API 650 for weld stress testing”, a knowledge graph can automatically link you to the exact section within API 650 (a 500-page document) that contains concepts on “weld stress testing”. No more guessing what part of that 500-page document you need, the graph will take you right there.
- Every piece of data is reusable and can be used to create derivative documents like work instructions, test plans, supplier instructions, internal specs, and more. Users can incorporate data by reference in MS Word and other document applications. No more duplicating work or manually rekeying content.
- Every piece of data is connected to its authoritative source, so even when you reuse data elements to create a new document, that new document contains links to the full context of the data.
- Since every piece of data is connected to its source, you always know its status (current, withdrawn, replaced, etc.) in real-time. You can easily avoid using a piece of data (or an entire document) that is out-of-date. Better still, readers can view a redline comparison in a single click.
- When data elements or documents are revised, you can view the impact in an instant throughout your entire enterprise, throughout your entire supply chain and digital thread. No more wondering where a document is being used or who/what is dependent on it; no more guessing the impact of your changes (and paying for your mistakes). The knowledge graph knows.
- Publishers and IP owners can measure the importance of their concepts–not just documents–by usage, relationships to other concepts, and other factors.
- Since the knowledge graph understands the concepts in each piece of data, you can easily extract requirements.
- The SWISS Knowledge Graph can be extended into various applications including web sites, MS Office, product lifecycle management (PLM) systems, engineering procurement and construction (EPC) systems, and even custom-built applications. Imagine building your own calculators or look-up tables simply by calling the right engineering data through an API.
Summary
The next time you look at an engineering document, don’t just think of it as a standalone document, think of it as a collection of data elements with complex relationships and uses. Consider how those concepts fit into a broader network of engineering knowledge. Now think about how much easier it would be to find, access, and use that information if it was linked together in a knowledge graph. That’s the promise of SWISS.